


建设新时代文明实践中心,是以习近平同志为核心的党中央从战略和全局出发作出的重大决策,是守正创新做好基层宣传思想工作的战略举措。
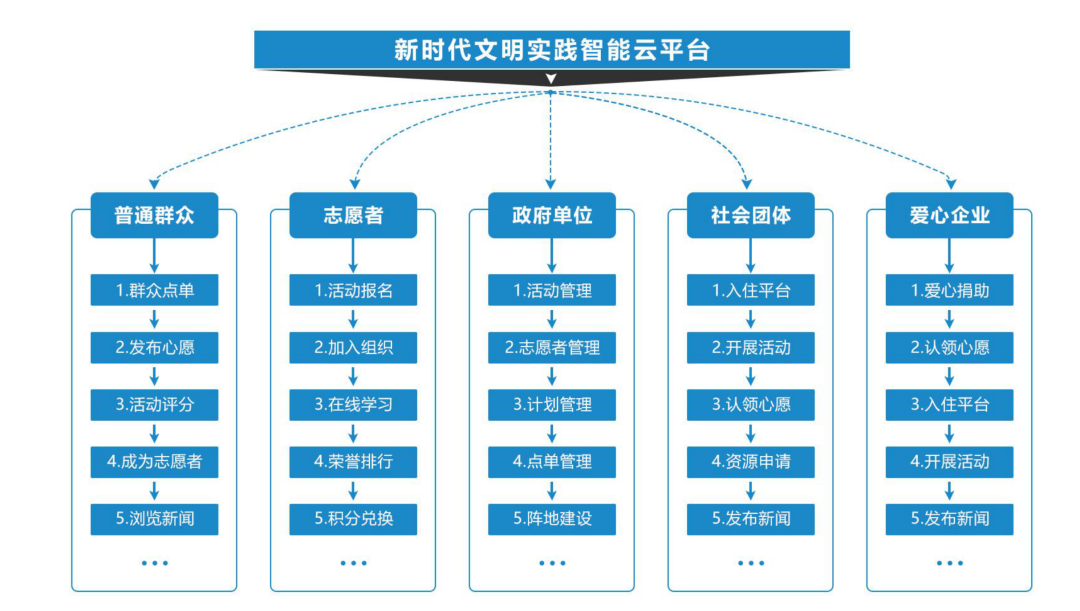
安徽福斯特信息技术有限公司持续助力新时代文明实践中心建设,充分利用大数据、云计算、移动互联网等新一代信息技术,打造新时代文明实践中心云平台,完善平台动员、整合、引导、服务、创新和保障能力,实现新时代文明实践中心的可持续运营。 福斯特新时代文明实践中心云平台集服务、管理、发布、展示于一体,推动平台、终端、和渠道互联互通,为基层党的理论宣讲、文化建设和为民服务提质增效,为志愿者、受益者与管理者提供了一个安全、快捷、便利、智慧化的新时代文明实践管理工具 借助“平台力量”,使现有各级各类资源焕发活力、配置优化、统筹使用、协同运行,把宣传教育与引导实践相结合,搭建与群众双向互动的沟通桥梁,增强群众对文明实践的理解支持,实现了文明志愿服务动态交互,充分发挥文明实践资源阵地的最大效能。 平台建设有助于扩大服务范围,强化服务手段,提高服务效率,实现线上+线下良性互助推动,同步发展、深度融合,对促进资源综合利用,提高服务创新能力形成“一呼百应”“应者云集”良好态势形成新时代文明实践中心建设的强大力量。

随着移动互联网趋势的推进和5G时代的来临,人们开始享受互联网带来更多的便利,日常生活和工作的很多环节都开始智能化。
安徽福斯特信息技术有限公司推出“媒体+政务+服务”模式,以网络媒介为基础“跨界融合”,正式推出“餐补消费系统”,助推实现媒体多功能板块的融合发展,让生活更美好,让世界更精彩。
——带你了解“餐补消费系统”
“餐补消费系统”立足于各党政企事业单位餐补消费,职工在app上进行实名注册后,各单位每月按照制定发放标准将餐补打入账户,通过app内入驻店铺进行消费。
借助官方主流媒体作用,通过融媒体宣传推广新模式,针对所有入驻商家定期推出星级商家评选宣传服务,与广大粉丝互动分享,吸引商家入驻平台,促进消费升级。
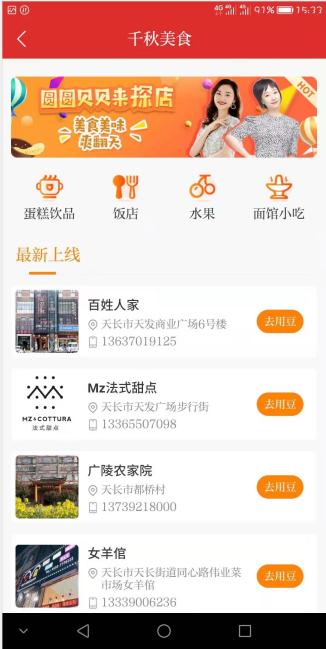
天长市融媒体中心成为安徽省首家使用“餐补消费系统”的单位,并更名为具有地方特色的“芡实豆”推广使用,现已成功合作近百家商户。
“餐补消费系统”的出现将更好的满足消费者品质化、多元化、便利化的消费需求,助力商家开启低成本高效益的营销模式,增加融媒体中心自身造血机能,打造城市经济品牌。